
How To Compress Drive To Save Disk Space Using NTFS Compression?
 Short Bytes: Microsoft Windows has abilities to compress your hard drive. The compression works for the drives formatted using the NTFS file system and for folders resting on an NTFS drive. You can also use NTFS compression on a pen drive by formatting it to NTFS.
Short Bytes: Microsoft Windows has abilities to compress your hard drive. The compression works for the drives formatted using the NTFS file system and for folders resting on an NTFS drive. You can also use NTFS compression on a pen drive by formatting it to NTFS.
The NTFS compression feature present in the Windows operating system comes handy when you want to squeeze your existing data to get some extra space. There are other useful methods for data compression but these require the data to be packed inside a zip or RAR file.
Shrinking files using NTFS compression will increase the workout done by your CPU while decompressing it. However, modern CPUs won’t give a sweat on this. Compressing the files won’t increase the access time. Instead, it may contribute lesser access time. This is because the files are first transferred to the RAM and then decompressed. A small-sized file could be transferred more quickly than a larger one.
An important point to be noted is that the compressions will only work for the stuff which can be compressed. This means that audio and video files, which are already compressed, won’t get shrunk considerably than the uncompressed ones like the word files and PDFs.
However, using NTFS compression on system files may not be beneficial to the health of your system. It may contribute to degradation in performance. It is not recommended to do so.
How To Compress Drive To Save Disk Space Using NTFS Compression?
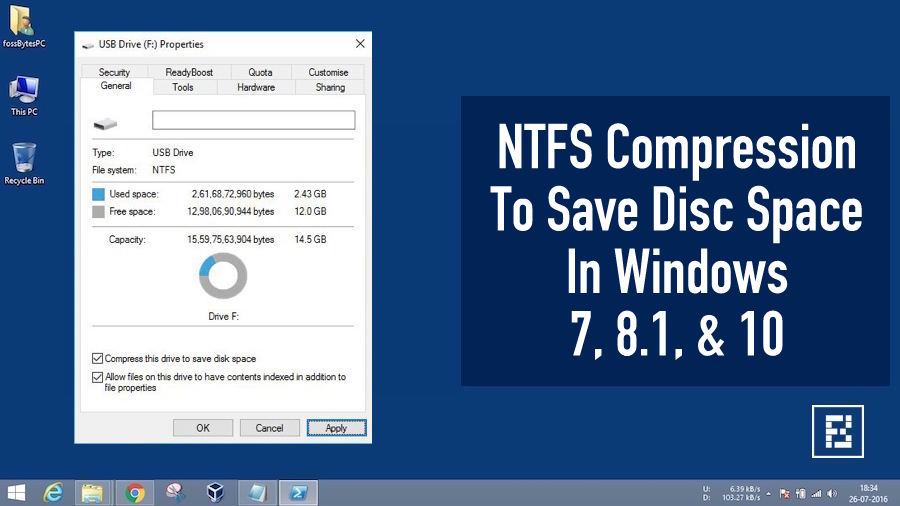
The drive that needs to be compressed should be formatted to use the NTFS file system. External storage devices like USB drives are formatted using the FAT32 file system. So, you’ll have to reformat it in order to enable NTFS compression.
Here are the steps to enable NTFS compression in Windows:
- Open My Computer/This PC.
- Right-click the desired drive and click Properties.
- Tick the checkbox for Compress drive to save disk space. Click Apply.
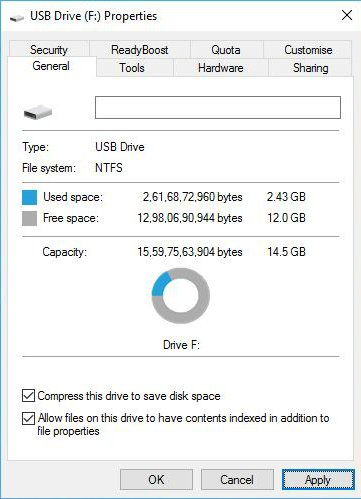
- Tick Apply changes to folder, subfolder, and files. Click Ok. It will take some time depending the size of your drive.
- To undo NTFS compression, untick the Compress drive to save disk space check box and follow similar steps.
How to compress contents of a folder to save space?
- Go to the Properties of that folder.
- Click Advanced.
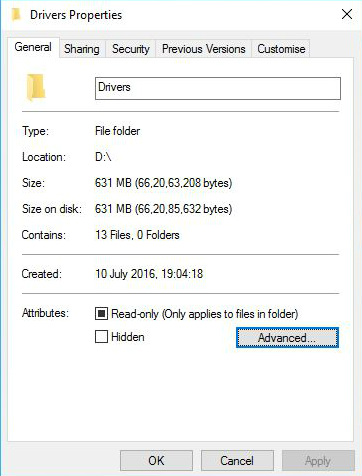
- Tick Compress contents to save disk space.
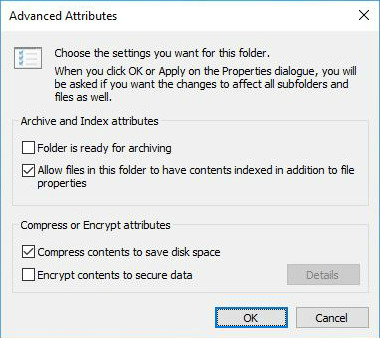
- Click Apply changes to this folder, sub folders and files. Click Ok.
- To undo NTFS compression, follow similar steps and untick Compress contents to save disk space.
Using NTFS compression to compress drives won’t drastically reduce your disk size. But it is good in the situations when you are out of space and want to store some important data, and also for keeping the files which you don’t use very often.
If you have something to add, tell us in the comments below.\
http://fossbytes.com/how-to-compress-drive-to-save-disk-space-using-ntfs-compression/






